Beyond the 2MB Limit: Inside the Proposed ICP Canister Workload Processing Pipeline Standard
Discover the proposed ICRC Canister Workload Processing Pipeline Standard, a robust framework designed to break through the 2MB message limit and cycle constraints on the Internet Computer. Learn how this community-driven spec enables multi-step, heavy-workload orchestration directly between canisters.
Key takeaways
- • Discover the proposed ICRC Canister Workload Processing Pipeline Standard, a robust framework designed to break through the 2MB message limit and cycle constraints on the Internet Computer
- • Learn how this community-driven spec enables multi-step, heavy-workload orchestration directly between canisters

Beyond the 2MB Limit: Inside the Proposed ICP Canister Workload Processing Pipeline Standard
As the Internet Computer (ICP) ecosystem transitions from simple, client-triggered actions toward complex, multi-step decentralized applications, developers are hitting fundamental infrastructure boundaries [1, 2]. While visual workflow interfaces like the recently launched B3Forge Flow Studio Beta [1] simplify browser-side execution using delegated identities [1, 2], a massive technical question remains: How do we handle heavy, multi-step data workloads directly on-chain between canisters?
To solve this, community developers have proposed the Canister Workload Processing Pipeline Standard (an upcoming ICRC standard draft) [2]. This standard addresses two of the most persistent bottlenecks in inter-canister communication: the 2MB message size limit and the per-round computing cycle limits [2].
Overcoming the 2MB Bottleneck with Chunked Pipelines
In a distributed canister environment, transferring large datasets (such as video files, AI model weights, or dynamic NFTs) directly in a single call is impossible due to the protocol's 2MB limit [2]. The proposed standard introduces a structured, stateful pipeline designed to split, process, and reassemble large datasets across canisters seamlessly [2].
At the heart of this specification is a state-machine-driven data flow that operates between a client canister (requestor) and a processor canister (executor) [2].
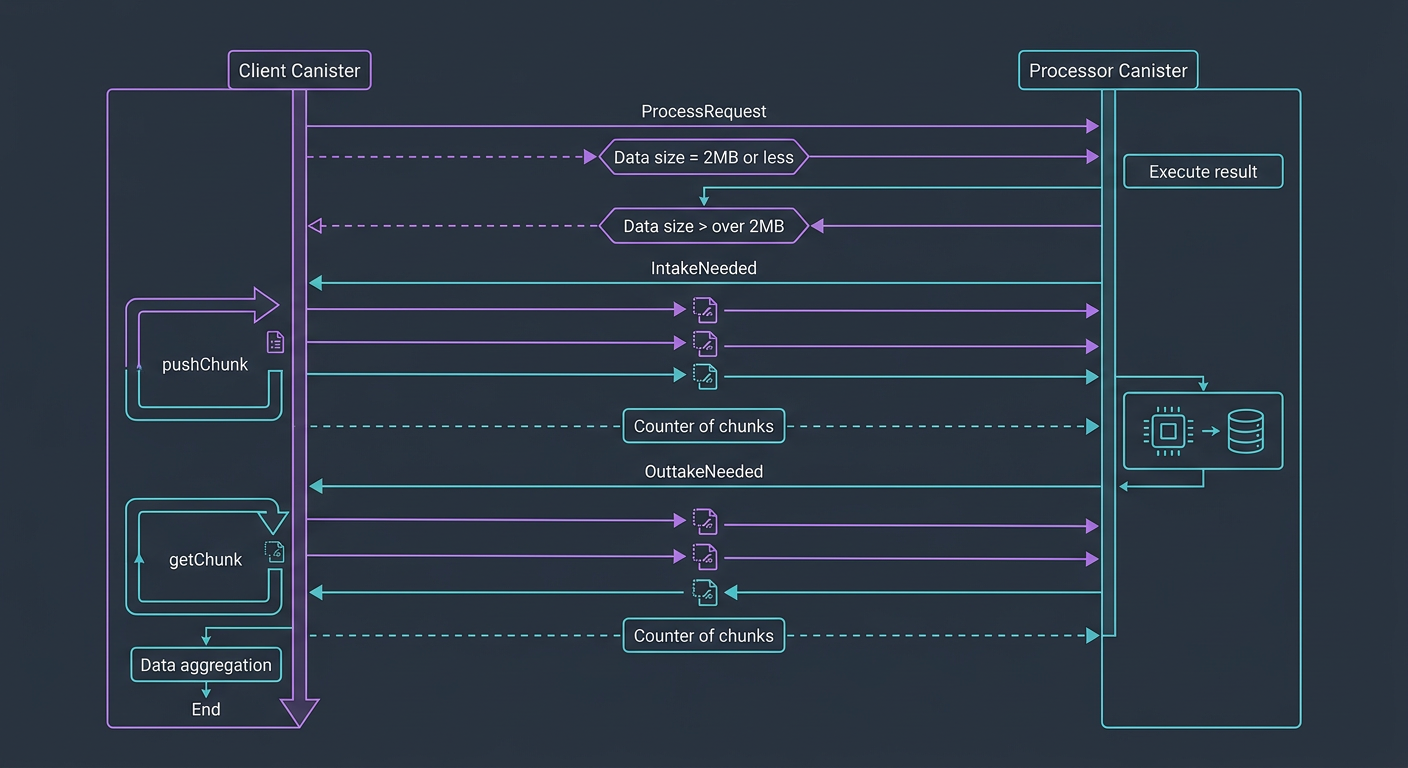
The Core Flow: Intake, Execution, and Outtake
- Initiate (
process): The client sends aProcessRequest[2]. If the payload is small (<2MB), it is processed immediately [2]. If it exceeds the limit, the canister returns an#IntakeNeededresponse [2]. - Data Streaming (
pushChunk): The caller streams the data in sequential chunks [2]. The processor maintains achunkMap(an array of booleans) to track and validate received chunks [2]. - Execution (
singleStepor#OnLoad): Processing can trigger automatically upon load (#OnLoadusing native canister timers) [2] or step-by-step manually (#Manualvia thesingleStepmethod) to stay safely within cycle limits [2]. - Retrieval (
getChunk): Once processing completes, if the resulting dataset is larger than 2MB, the canister signals#OuttakeNeeded[2]. The client then pulls the finalized dataset chunk-by-chunk [2].
Technical Architecture: Important Types
To ensure interoperability, the standard defines strictly typed data structures using Candid-native expressions [1, 2]:
The ProcessRequest Type
public type ProcessRequest = {
event: ?Text; // Namespace for routing/logging
caller: ?Principal; // Authorization identity
expiresAt : ?Int; // Expiration timestamp
dataConfig: ?DataConfig; // #DataIncluded, #Local, #Push, or #Internal
executionConfig: ?ExecutionConfig; // #OnLoad or #Manual
responseConfig: ?ResponseConfig; // #Include, #Pull, or #Local
};
The dataConfig variant is particularly powerful, letting the canister know whether to expect an immediate payload, a reference to local canister storage, or a stream of chunked uploads [2].
The ProcessResponse Type
public type ProcessResponse = ?{
#DataIncluded: ?{ payload: [CandyTypes.AddressedChunk] };
#Local : Nat;
#IntakeNeeded: ?{ pipeInstanceID: PipeInstanceID; currentChunks: Nat; totalChunks: Nat; chunkMap: [Bool] };
#OuttakeNeeded: ?{ pipeInstanceID: PipeInstanceID };
#StepProcess: ?{ pipeInstanceID: PipeInstanceID; status: ProcessType };
#Assigned: { pipeInstanceID: PipeInstanceID; canister: Principal };
};
The response serves as a state indicator, routing the calling canister to either send more data (#IntakeNeeded), retrieve results (#OuttakeNeeded), or track multi-step progress (#StepProcess) [2].
Moving Toward Fully Autonomous On-Chain Agents
While browser-side workflows (like those built in B3Forge Flow Studio) rely on manual triggers [1], the future of Web3 requires "always-on" automation [2]. This proposed standard bridges that gap [2]. By standardizing how canisters push, process, and pull heavy workloads, developers can build visual workflows that compile directly into autonomous, on-chain canister pipelines [1, 2].
This evolution eliminates reliance on manual client-side delegations [2], moving the Internet Computer closer to a fully automated, decentralized cloud engine [2].
Tags
What to read next

The "Friday the 13th" Bug: Inside the ckBTC Double-Minting Postmortem
The Battle Over Geopolitics in Web3: Inside Internet Computer’s Rejected "G20 Subnet" Proposal

The Double-Time Shift: Why Internet Computer's Internet Identity is Moving to a Twice-Weekly Release Cadence
Enjoyed this? Get the next one
Subscribe to the newsletter and the next playbook lands in your inbox — no spam, unsubscribe anytime.