The MIT-Licensed Heavyweight: How Z.ai’s GLM-5.2 is Shaking Up the Global AI Order
Beijing-based Z.ai has released GLM-5.2, a 744-billion-parameter Mixture-of-Experts (MoE) model under a permissive MIT license. Delivering near-proprietary coding performance at up to one-sixth the API cost of Western alternatives, it signals a major power shift to open-weight AI.
Key takeaways
- • Beijing-based Z.ai has released GLM-5.2, a 744-billion-parameter Mixture-of-Experts (MoE) model under a permissive MIT license
- • Delivering near-proprietary coding performance at up to one-sixth the API cost of Western alternatives, it signals a major power shift to open-weight AI

The MIT-Licensed Heavyweight: How Z.ai’s GLM-5.2 is Shaking Up the Global AI Order
The debate between closed-source superiority and open-weight flexibility has officially entered a new era. Beijing-based AI pioneer Z.ai (formerly Zhipu AI) has released GLM-5.2, a massive 744-billion-parameter Mixture-of-Experts (MoE) foundation model. Crucially, Z.ai has bypassed proprietary gates entirely, distributing the weights under a highly permissive, unrestricted MIT license with no regional locks.
As developers globally grapple with the rising costs of closed APIs and sudden geopolitical access shifts, GLM-5.2 offers a free, downloadable lifeline that matches—and in some areas exceeds—the Western proprietary frontier.
Behind the Tech: IndexShare and Speculative Decoding
GLM-5.2 is not just a brute-force scale-up; it is a masterclass in modern hardware optimization. Developed and trained entirely on domestic Huawei Ascend chips, the model features a massive 1-million-token context window and a staggering 131,072-token output capacity.
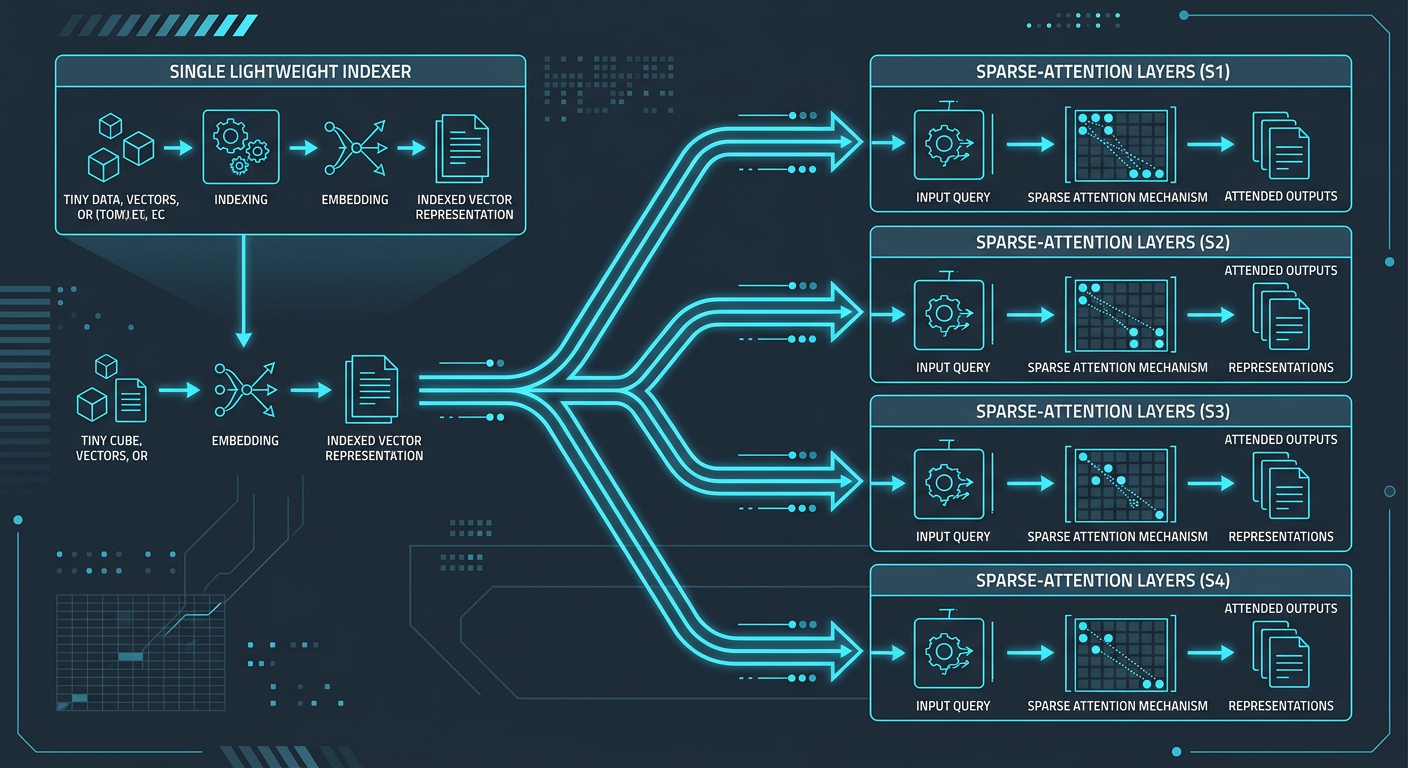
To manage the heavy compute demands of active 1M-token environments, Z.ai introduced two key architectural innovations to lower the computational ceiling:
- IndexShare: By sharing one lightweight indexer across every four sparse-attention (DSA) layers, GLM-5.2 reduces per-token FLOPs by 2.9x at maximum context.
- Multi-Token Prediction (MTP): For speculative decoding, GLM-5.2 incorporates an improved MTP layer that boosts token acceptance length by up to 20%, resulting in dramatically faster inference times.
Shaking Up the Benchmark Leaderboards
In practical application, GLM-5.2 is designed for "doing" rather than just chatting, aiming to function as an independent digital teammate that can execute long-term projects with minimal human assistance.
The model’s scorecard reveals some of the most striking numbers of 2026:
- Terminal-Bench 2.1: Scoring an outstanding 81.0% (up from 62.0% in GLM-5.1), GLM-5.2 has crossed the critical threshold where an AI agent can reliably execute terminal-based tasks without constant human babysitting.
- SWE-bench Pro: It scores 62.1%, comfortably edging past GPT-5.5 (58.6%) and sitting just under Anthropic's flagship Claude Opus 4.8.
- AIME 2026: It achieved a nearly perfect 99.2% on Olympiad-level mathematics.
The Economic Reality
For enterprise teams, the true disruption lies in the financial calculus. Via API, GLM-5.2 is priced at $1.40 per million input tokens and $4.40 per million output tokens. This represents a staggering 6x cost reduction compared to Western proprietary giants, fundamentally shifting the ROI of production-grade AI agents. With GLM-5.2, the shift toward highly capable, cost-efficient open-source AI is no longer a future prediction—it is a production-ready, open-weight reality.
Tags
Grounded sources & citations
What to read next

The $35B AI XPV Alliance: How Private Credit and Custom Silicon Are Bypassing Nvidia

No More Hand-Me-Downs: How Microsoft’s MAI-Thinking-1 Kills the OpenAI Dependency

GPT-5.6 Unveiled: OpenAI Launches Sol, Terra, and Luna Under U.S. Government Review
Enjoyed this? Get the next one
Subscribe to the newsletter and the next playbook lands in your inbox — no spam, unsubscribe anytime.